
The great majority of attacks, including targeted attacks, start with a link in an email, chat or sms. Phishing websites have been on the rise for the last decade, and their number is even bigger than websites hosting malware. Nowadays it’s easy to become a victim of such attacks, mostly when under pressure or when it’s hard to verify if the URL we clicked on is the right one. For this reason Should I Click was born. In this blog post we would like to introduce this new service, how it works, and how it can help protect our civil society from digital threats.
Unsafe websites detected per week by Google Safe Browsing, from 2007 to 2020. Source: https://transparencyreport.google.com/safe-browsing/overview
What is Should I Click?
“Should I Click” is a free online web service that helps users decide if they should click on a suspicious link or not. This service was born as part of the master thesis of František Střasák. Should I Click uses machine learning systems that were trained with thousands of real websites used for attacks. For every submitted URL, the service will not only tell you if it’s safe to click or not, but Should I Click is also able to tell you why.
Should I Click free online web service is able to analyze a URL and indicate if its safe to click or not and why.
How does it work?
Once the user inserts the URL to check, the service will automatically download all possible information from the website, will extract features from the downloaded resources, and will run a series of machine learning algorithms to process these features and give a final verdict.
The data from the website is accessed directly from Civilsphere servers, and also using the service https://urlscan.io/. The service also runs special virtual machines to analyze in real time if the JavaScript code of the webpage is trying to attack your browser or not. After all the data is processed, features are extracted and the machine learning algorithms give a verdict on the URL.
Example of an analysis of Should I Click where the verdict is that the user should click on the link as there were no potential threats detected on the Google Accounts website.
Example of an analysis of Should I Click where the verdict is that the user should not click on the link due to the website likely being a fake version of a known news site.
Should I Click Under The Hood
There are many reasons why a user should not click on a link. Currently an ongoing project, in its beta-version Should I Click is trained to detect four types of websites: evil twin websites, scam websites, websites with dangerous behavior, and websites with bad HTTPS practices. Each of these classes of websites are described below.
EVIL TWIN WEBSITES
Evil twin websites are websites designed to look the same as a normal website but are completely controlled by the attacker. These are used as phishing techniques to steal emails, passwords, credit card numbers and other sensitive data. Evil twin websites success is based on users’ visual perception: the user needs to perceive the evil twin website as completely normal. When done properly, Evil twin websites are very hard to detect.
The only way for users to detect if a website is an evil twin is to check the URL they are accessing every time to make sure it is the correct website they want to visit.
Example of a real Google identity verification page. We can see that the domain is accounts.google.com with a valid HTTPS certificate.
Example of an evil twin website attempting to imitate a Google identity verification page. However we can see that the domain is "minivale.com" and not Google Accounts.
SCAM WEBSITES
As the previous type, Scam websites are also phishing techniques. However scam websites often offer fake products to users with the aim to steal their credentials. In most cases all this happens under time pressure. For instance, “You won a new iPhone7 and you have only 60 seconds to fill this information to get this phone.”).
For experienced users, scam websites are not difficult to detect because they have patterns that are easy to recognize. However, these patterns so evident for a human are a very difficult task for a machine learning algorithm: the patterns the human can identify are difficult to translate into features for algorithms.

Example of a scam website, offering a free iPhone to the user to steal his personal data.
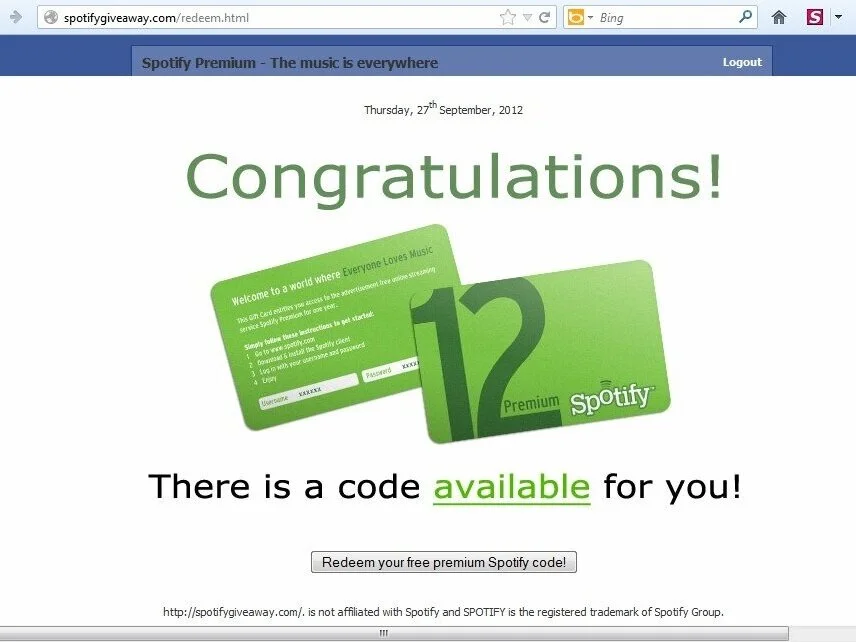
Example of a scam website, offering a Spotify code to get a free premium subscription.
WEBSITES WITH DANGEROUS BEHAVIOR
In this category we include a wide range of malicious websites. It can mean they contain harmful JavaScript, cryptojacking attacks, or exploits. All these different attacks are designed to attack the web browser of the user and in the end, infect or abuse the device. The presence of these attacks are difficult to recognize from a user point of view. For machine learning algorithms this proves to be also a difficult task and this complexity translates to results being always not good enough.
WEBSITES WITH BAD HTTPS PRACTICES
In this category we include all websites that handle users data without proper encryption. Most of these websites are not malicious, however the lack of encryption makes them vulnerable to attacks such as man-in-the-middle or redirection attacks. Furthermore users should be even more suspicious if a website has no HTTPS but there is an input form for sensitive data such as: email, password or credit card number. Additionally, Should I Click also verifies the HTTPS certificate validity, if it’s expired or has an unknown certificate issuer. While this type of certificate issues are shown as warning in today’s browsers, it is important to also include them in our analysis and evaluation.
Your Feedback Makes Should I Click Better
Should I Click uses your feedback to get better. If you know a website is malicious or benign, and the verdict by Should I Click is wrong, we urge you to use the feedback form to give us feedback. This helps adjust our algorithms and be able to provide better verdicts in the future.
We hope Should I Click will help protect the civil society and reduce the number of successful attacks. We hope Should I Click will help you. The best place to start is here: www.shouldiclick.org.